# Recipe: 单步偏移策略异步训练器
**作者:** `https://github.com/meituan-search`
最后更新:07/17/2025。
## 简介
### 背景
当前,verl 实现的强化学习训练过程是同步的,遵循了 PPO、GRPO 和 DAPO 等成熟方法的算法工作流。在每个步骤中,训练样本由最新模型生成,且模型在训练完成后才会更新。虽然这种方法符合离线策略强化学习并稳定了 RL 训练,但它存在严重的效率问题。模型更新必须等待生成阶段中最长的输出完成。在生成长尾样本时,GPU 处于空闲状态,导致显著的资源利用不足。样本生成的尾部延迟问题越严重,整体训练效率就越低。例如,在 DAPO 32B 训练中,Rollout 阶段约占总时间的 70%,而增加资源并不能减少 Rollout 持续时间。
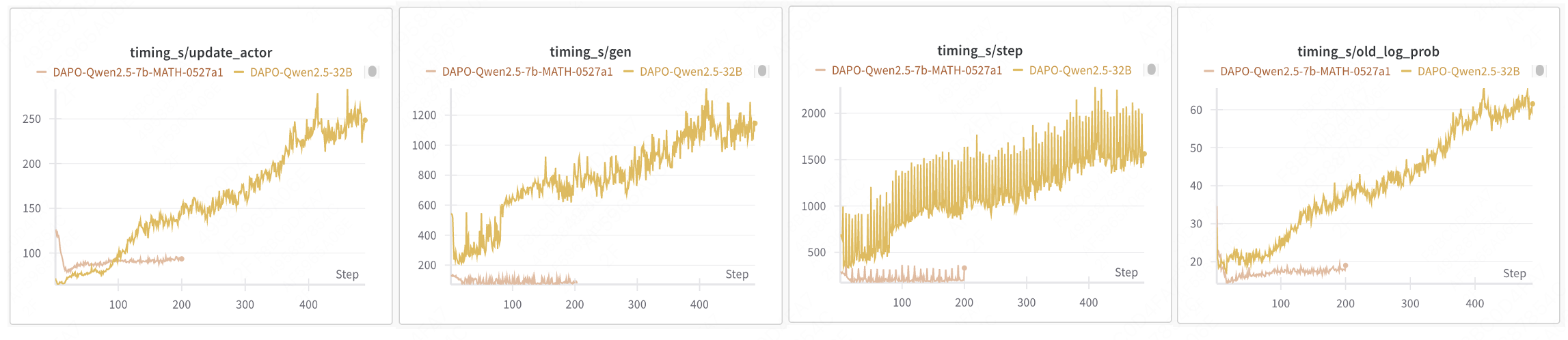
> 数据来源:https://wandb.ai/verl-org/DAPO%20Reproduction%20on%20verl/workspace?nw=nwusertongyuxuan361
### 解决方案
我们实现了 **单步偏移异步训练器** 来缓解这一问题。这种方法将生成和训练过程并行化,在当前训练使用上一步生成的样本时,同时生成下一批样本。它还适当划分资源,为生成分配专用资源,剩余资源自动分配给训练。通过减少分配给生成阶段的资源,我们减轻了长尾样本生成期间 GPU 的空闲时间。在此过程中,生成和训练参数保持一步偏移策略。

> 参考:[AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning](
> https://arxiv.org/abs/2505.24298)
我们的核心贡献包括:
1. **并行生成和训练**:
下一批样本的异步生成与当前批次的训练同时进行。
2. **资源隔离**:
与 `hybrid_engine` 不同,这种方法需要为 rollout 显式分配资源,剩余资源自动分配给训练。
3. **NCCL 参数同步**:
使用 NCCL 通信原语实现生成和训练模块之间的无缝参数传输。
### 实验结果
- **机器配置**:每台有 16 个 H20 GPU 的 2 个节点
- 生成:4 个 GPU
- 训练:12 个 GPU
- **模型**:Qwen2.5-Math-7B
- **Rollout 配置**:
- **最大响应长度**:FSDP2:20,480 个 token;Megatron:8,192 个 token
- **算法**:DAPO
- **Rollout 引擎**:vLLM
| 训练模式 | 引擎 | 步骤 | gen | wait_prev_gen | generate_sequences | old_log_prob | update_actor | 总时间 | acc/best@32/mean | acc/maj@32/mean |
|-----------------------|-------------|------|-----|---------------|--------------------|--------------|--------------|--------------|------------------|-----------------|
| colocate sync | VLLM+FSDP2 | 749 | 321 | - | 247 | 88 | 286 | 19h18m | 0.5948 | 0.417 |
| one-step-overlap async | VLLM+FSDP2 | 520 | - | 45 | 458 | 108 | 337 | 15h34m(+23%) | 0.6165 | 0.494 |
| colocate sync | VLLM+Megatron | 699 | 207 | - | 162 | 119 | 344 | 18h21m | 0.605 | 0.4217 |
| one-step-overlap async | VLLM+Megatron | 566 | - | 59 | 501 | 120 | 347 | 13h06m (+40%) | 0.6569 | 0.4038 |
* colocate sync:步骤 ≈ gen + old_log_prob + update_actor
* one-step-overlap async:步骤 ≈ wait_prev_gen + old_log_prob + update_actor
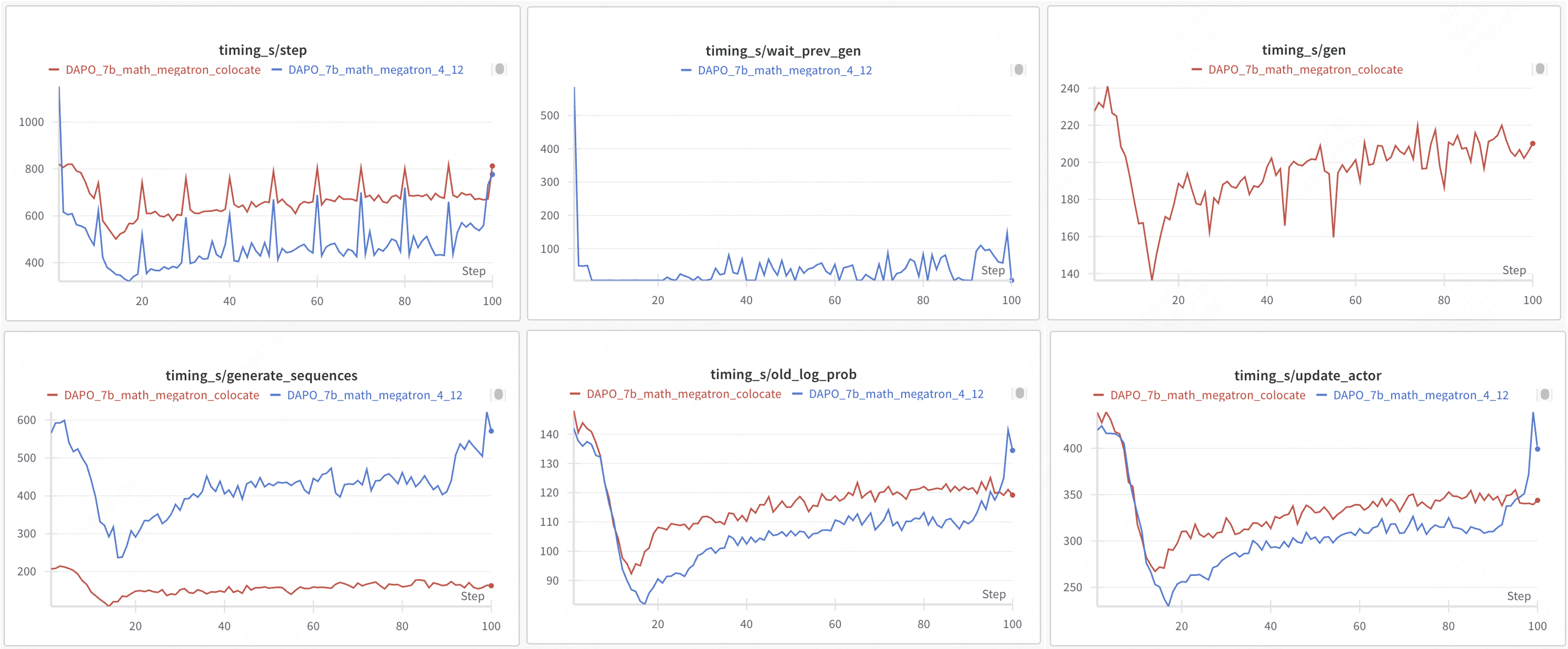
> 数据来源:https://wandb.ai/hou-zg-meituan/one-step-off-policy?nw=nwuserhouzg
## 实现
### 单步偏移策略异步管道
我们实现的 **单步偏移策略异步管道** 以最小成本无缝集成到现有训练逻辑中,无需额外样本存储管理。核心机制使用 `async_gen_next_batch` 进行异步 rollout 生成,并在周期转换期间通过 `create_continuous_iterator` 保持连续操作。
```python
# 迭代器生成器,简化训练过程中的一步集成
def _create_continuous_iterator(self):
for epoch in range(self.config.trainer.total_epochs):
iterator = iter(self.train_dataloader)
for batch_dict in iterator:
yield epoch, batch_dict
# 读取下一批样本,参数同步并启动异步 gen_seq
def _async_gen_next_batch(self, continuous_iterator):
# 读取 train_data
try:
epoch, batch_dict = next(continuous_iterator)
except StopIteration:
return None
batch = DataProto.from_single_dict(batch_dict)
gen_batch = batch_pocess(batch)
# 从 actor 到 rollout 同步权重
self.sync_rollout_weights()
# 异步生成
gen_batch_output = self.rollout_wg.async_generate_sequences(gen_batch)
# future 封装
return GenerationBatchFuture(epoch, batch, gen_batch_output)
continuous_iterator = self._create_continuous_iterator()
# 首次运行 rollout 以实现一步偏移
batch_data_future = self._async_gen_next_batch(continuous_iterator)
while batch_data_future is not None:
# 等待上一步的 gen_seq 结果
batch = batch_data_future.get()
# 启动下一次异步生成序列的调用
batch_data_future = self._async_gen_next_batch(continuous_iterator)
# 计算优势
batch = critic.compute_values(batch)
batch = reference.compute_log_prob(batch)
batch = reward.compute_reward(batch)
batch = compute_advantages(batch)
# 模型更新
critic_metrics = critic.update_critic(batch)
actor_metrics = actor.update_actor(batch)
```
### 参数同步
有趣的是,我们基于 NCCL 的 rollout 模型权重更新性能优秀。大多数情况下延迟低于 300ms,这对 RLHF 是可以忽略不计的。
> **sync_rollout_weights**:从 actor 到 rollout 同步参数的时间极快,几乎可以忽略,因为它是基于 NCCL 实现的。
```python
class ActorRolloutRefWorker:
# actor 获取模型参数的元信息以进行参数同步
@register(dispatch_mode=Dispatch.ONE_TO_ALL)
def get_actor_weights_info(self):
params = self._get_actor_params()
ret = []
for key, tensor in params.items():
ret.append((key, tensor.size(), tensor.dtype))
self._weights_info = ret
return ret
# rollout 设置模型参数的元信息以进行参数同步
@register(dispatch_mode=Dispatch.ONE_TO_ALL)
def set_actor_weights_info(self, weights_info):
self._weights_info = weights_info
class AsyncRayPPOTrainer(RayPPOTrainer):
def init_workers(self):
...
# rollout 从 actor 获取模型参数的元信息以进行参数同步
weights_info = self.actor_wg.get_actor_weights_info()[0]
self.rollout_wg.set_actor_weights_info(weights_info)
# 创建 actor-rollout 通信组以进行参数同步
self.create_weight_sync_group
```
```python
# 驱动过程分别调用 actor 和 rollout,以基于 NCCL/hccl 创建权重同步组。
def create_weight_sync_group(self):
master_address = ray.get(self.actor_wg.workers[0]._get_node_ip.remote())
master_port = ray.get(self.actor_wg.workers[0]._get_free_port.remote())
world_size = len(self.actor_wg.workers + self.rollout_wg.workers)
self.actor_wg.create_weight_sync_group(
master_address,
master_port,
0,
world_size,
)
ray.get(
self.rollout_wg.create_weight_sync_group(
master_address,
master_port,
len(self.actor_wg.workers),
world_size,
)
)
# 驱动过程分别调用 actor 和 rollout 通过 NCCL 同步参数
def sync_rollout_weights(self):
self.actor_wg.sync_rollout_weights()
ray.get(self.rollout_wg.sync_rollout_weights())
# FSDP 模型参数同步
@register(dispatch_mode=Dispatch.ONE_TO_ALL, blocking=False)
def sync_rollout_weights(self):
params = self._get_actor_params() if self._is_actor else None
if self._is_rollout:
inference_model = (
self.rollout.inference_engine.llm_engine.model_executor.driver_worker.worker.model_runner.model
)
from verl.utils.vllm.patch import patch_vllm_moe_model_weight_loader
patch_vllm_moe_model_weight_loader(inference_model)
# 模型参数从 actor 到 rollout 张量逐一广播
for key, shape, dtype in self._weights_info:
tensor = torch.empty(shape, dtype=dtype, device=get_torch_device().current_device())
if self._is_actor:
assert key in params
origin_data = params[key]
if hasattr(origin_data, "full_tensor"):
origin_data = origin_data.full_tensor()
if torch.distributed.get_rank() == 0:
tensor.copy_(origin_data)
from ray.util.collective import collective
collective.broadcast(tensor, src_rank=0, group_name="actor_rollout")
if self._is_rollout:
inference_model.load_weights([(key, tensor)])
```
## 使用方法
### FSDP2 配置示例
```shell
python3 -m recipe.one_step_off_policy.async_main_ppo \
--config-path=config \
--config-name='one_step_off_ppo_trainer.yaml' \
actor_rollout_ref.actor.strategy=fsdp2 \
# actor 和 rollout 分开放置
actor_rollout_ref.hybrid_engine=False \
# actor 和 rollout 资源
trainer.nnodes=1 \
trainer.n_gpus_per_node=6 \
rollout.nnodes=1 \
rollout.n_gpus_per_node=2
```
### Megatron 配置示例
```shell
python3 -m recipe.one_step_off_policy.async_main_ppo \
--config-path=config \
--config-name='one_step_off_ppo_megatron_trainer.yaml' \
actor_rollout_ref.actor.strategy=megatron \
# actor 和 rollout 分开放置
actor_rollout_ref.hybrid_engine=False \
# actor 和 rollout 资源
trainer.nnodes=1 \
trainer.n_gpus_per_node=6 \
rollout.nnodes=1 \
rollout.n_gpus_per_node=2
```
### 配置指南
1. **卡数关系**
为最佳批次分布,保持以下关系之一:
- `actor_rollout_ref.rollout.n` 应该是 `trainer.n_gpus_per_node * trainer.nnodes` 的整数因子
- `actor_rollout_ref.rollout.n * data.train_batch_size` 应该被 `trainer.n_gpus_per_node * trainer.nnodes` 整除
> 理由:确保在使用部分资源进行生成时,训练样本可以均匀分布在训练 GPU 上。
2. **动态资源调整**
根据阶段持续时间调整 `trainer.nnodes` `trainer.n_gpus_per_node` `rollout.nnodes` `rollout.n_gpus_per_node`:
- **理想状态**:Rollout 和训练阶段持续时间相近
- **诊断指标**:
- 监控 `wait_prev_gen` 持续时间
- 分析 `sequence_length` 分布
- **调整策略**:
- 高 `wait_prev_gen` + 均匀序列长度 → 增加 rollout 资源
- 高 `wait_prev_gen` + 长尾序列 → 优化停止标准(增加资源不会帮助)
> **wait_prev_gen**:等待上一个 rollout 结束的时间(未完全重叠的部分)。
**资源配置策略:**
- **资源受限场景**:通过调整 GPU 分配比例优化资源利用率,保持节点数相等以允许训练和 rollout 共享节点;
- 配置 `trainer.nnodes = rollout.nnodes`,且 `trainer.n_gpus_per_node + rollout.n_gpus_per_node = physical_gpus_per_node`。通过调整 `n_gpus_per_node` 来控制 rollout 资源分配。
- **资源充足场景**:通过调整节点数量优化性能,保持每节点 GPU 数相等以实现训练和 rollout 并行性的独立扩展。
- 配置 `trainer.n_gpus_per_node = rollout.n_gpus_per_node`,并通过调整 `trainer.nnodes` 和 `rollout.nnodes` 以实现最佳性能。
> **注意**:系统所需的总节点数并非简单地是 `trainer.nnodes + rollout.nnodes`。实际计算取决于 GPU 容量:
> - 当 `trainer.n_gpus_per_node + rollout.n_gpus_per_node <= physical_gpus_per_node` 时,
> 所需节点数为 `max(trainer.nnodes, rollout.nnodes)`
> - 当 `trainer.n_gpus_per_node + rollout.n_gpus_per_node > physical_gpus_per_node` 时,
> 所需节点数为 `trainer.nnodes + rollout.nnodes`
## 功能支持
| 类别 | 支持情况 |
|--------------------|-----------------------------------------------------------------------------------------------------------------|
| 训练引擎 | FSDP2
Megatron |
| rollout 引擎 | vLLM |
| AdvantageEstimator | GRPO
GRPO_PASSK
REINFORCE_PLUS_PLUS
RLOO
OPO
REINFORCE_PLUS_PLUS_BASELINE
GPG |
| Reward | 全部 |